Last week, while sharing the article “My Journey to Becoming an AI Product Manager,” I hinted that I would produce a comprehensive piece to help everyone systematically learn about large models. Today, I am delivering that article; it totals 22,000 words and is expected to take about 30 minutes to read, covering 15 topics related to large models.

In the past year, there has been an overwhelming amount of articles introducing and explaining large models. Most people already have some foundational knowledge, but I feel that this information is too fragmented and lacks a systematic understanding. Currently, there is no article that comprehensively explains what large models are in one go.
To alleviate my own cognitive anxiety, I decided to summarize the knowledge I have gained about large models over the past year into this article. I hope to clarify my understanding of large models through this single article, which serves as a testament to my extensive learning.
What Will I Share?
This article will share 15 topics related to large models. Originally, there were 20 topics, but I removed some that were more technical and focused on issues that ordinary users or product managers should pay attention to. The goal is to ensure that as AI novices, we only need to master and understand these key points.
Who Is This For?
This article is suitable for the following groups of friends:
- Those who want to understand what large models are all about.
- Individuals looking to transition into AI-related products and roles, including product managers and operations personnel.
- Those who have a basic understanding of AI but wish to advance their knowledge and reduce cognitive anxiety about AI.
Content Disclaimer: The entire content is a result of my personal synthesis after extensive reading and digestion of numerous expert articles, books related to large models, and consultations with industry experts. I primarily serve as a knowledge synthesizer; if any descriptions are incorrect, please feel free to inform me kindly!
Lecture 1: Understanding Common Concepts of Large Models
Before diving into large models, let’s first understand some foundational concepts. Grasping these professional terms and their relationships will benefit your subsequent reading and learning of any AI and large model-related content. I spent considerable time organizing their relationships, so please read this section carefully.
1. Common AI Terms
1) Large Model (LLM): All existing large models refer to large language models, specifically generative large models, with practical examples including GPT-4.0 and GPT-4o.
- Deep Learning: A subfield of machine learning focused on using multi-layer neural networks for learning. Deep learning excels at processing complex data such as images, audio, and text, making it highly effective in AI applications.
- Supervised Learning: A machine learning method where the model learns the mapping from input to output using a labeled dataset. Common algorithms include linear regression, logistic regression, support vector machines, K-nearest neighbors, decision trees, and random forests.
- Unsupervised Learning: A machine learning method that discovers patterns and structures in data without labeled data. Common algorithms include K-means clustering, hierarchical clustering, DBSCAN, principal component analysis (PCA), and t-SNE.
- Semi-supervised Learning: Combines a small amount of labeled data with a large amount of unlabeled data for training. It leverages the rich information from unlabeled data and the accuracy of labeled data to improve model performance. Common methods include Generative Adversarial Networks (GANs) and autoencoders.
- Reinforcement Learning: A method that learns optimal strategies through interaction with the environment, based on reward and punishment mechanisms. Common algorithms include Q-learning, policy gradients, and Deep Q-Networks (DQN).
- Model Architecture: Represents the design of the backbone of the large model. Different architectures affect the model’s performance, efficiency, and computational costs, and determine the model’s scalability.
- Transformer Architecture: The mainstream architecture used by most large models, including GPT-4.0 and many domestic large models. The widespread use of the Transformer architecture is mainly because it enables large models to understand human natural language, maintain contextual memory, and generate text.
- MOE Architecture: Stands for Mixture of Experts architecture, which combines various expert models to form a massive model capable of addressing multiple complex professional problems.
- Machine Learning Techniques: A broad category of techniques that enable AI, including deep learning, supervised learning, and reinforcement learning. As a product manager, you don’t need to delve too deeply into these; just understand the relationships between these methods.
- NLP Technology (Natural Language Processing): A field of AI focused on enabling computers to understand, interpret, and generate human language for applications like text analysis, machine translation, speech recognition, and dialogue systems.
- CV Technology (Computer Vision): If NLP deals with text, CV addresses visual content-related technologies, including common image recognition, video analysis, and image segmentation techniques.
- Speech Recognition and Synthesis Technology: Includes converting speech to text and synthesizing speech, such as Text-to-Speech (TTS) technology.
- Retrieval-Augmented Generation (RAG): Refers to the technology where large models generate content based on information retrieved from search engines and knowledge bases, commonly involved in AI applications.
- Knowledge Graph: A technology that connects knowledge, allowing models to better and faster access the most relevant information, thereby enhancing their ability to process complex associative information and AI reasoning.
- Function Call: In large language models (like GPT), it refers to calling built-in or external functions to perform specific tasks or operations. This mechanism allows models to execute diverse and specific operations beyond mere text generation.
2) Terms Related to Large Model Training and Optimization Techniques
- Pre-training: The process of training a model on a large dataset, typically diverse, to obtain a model with strong general capabilities.
- Fine-tuning: Further training a large model on specific tasks or smaller datasets to improve its performance on targeted issues, using vertical domain data.
- Prompt Engineering: In product manager terms, it refers to crafting questions in a way that the large model can easily understand, enhancing the input for desired results.
- Model Distillation: A technique that transfers knowledge from a large model (teacher model) to a smaller model (student model) to improve performance while retaining much of the large model’s accuracy.
- Model Pruning: The process of removing unnecessary parameters from a large model to reduce its overall size and computational costs.
3) AI Application-Related Terms
- Agent: An AI application with a specific capability, akin to how applications in the internet era were called apps.
- Chatbot: Refers to AI chatbots, a type of AI application that interacts through conversation, including products like ChatGPT.
4) Terms Related to Large Model Performance
- Emergence: Refers to the phenomenon where a large model exhibits capabilities beyond expectations once its parameter scale reaches a certain threshold.
- Hallucination: Indicates instances where a large model generates nonsensical content, mistakenly treating incorrect facts as true, leading to unrealistic outputs.
- Amnesia: Refers to the situation where, after a certain number of dialogue turns or length, the model suddenly forgets previous context, leading to repetition and memory loss.
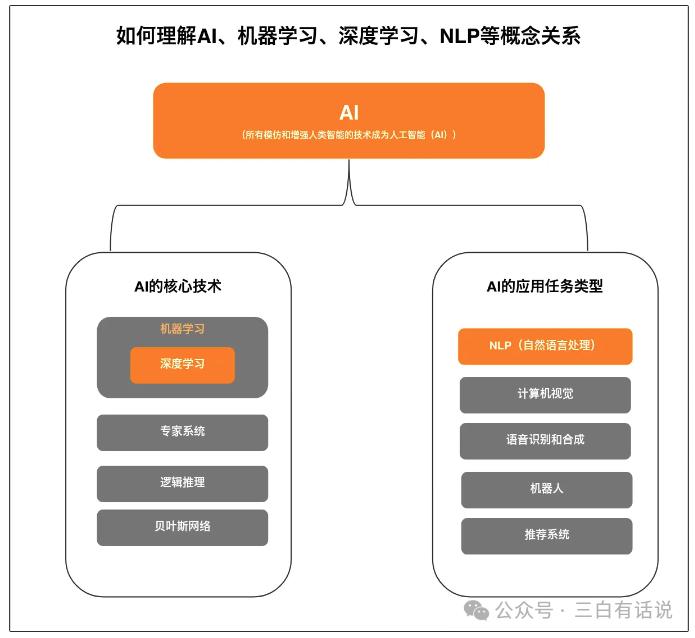
2. Understanding the Relationship Between AI, Machine Learning, Deep Learning, and NLP
If you are interested in AI and large models, you will inevitably encounter keywords like “AI,” “Machine Learning,” “Deep Learning,” “NLP” in your future studies. Therefore, it’s best to clarify these professional terms and their logical relationships to facilitate easier understanding.
In summary, the relationships between these concepts are as follows:
- Machine learning is a core technology of AI, alongside expert systems and Bayesian networks (no need to delve into these).
- NLP is a type of application task within AI focused on natural language processing, while AI’s application technologies also include CV technology, speech recognition, and synthesis.
3. Understanding the Transformer Architecture
When discussing large models, one cannot overlook the Transformer architecture. If large models are like a tree, the Transformer architecture serves as the trunk. The emergence of products like ChatGPT is primarily due to the design of the Transformer architecture, which enables models to understand context, maintain memory, and predict new words. Moreover, the Transformer allows large models to train on unlabeled data, eliminating the need for extensive labeled data preparation.
Relationship Between Transformer Architecture and Deep Learning Technology: The Transformer architecture is a type of neural network architecture within the deep learning field. Other architectures include traditional Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTM) networks.
4. Understanding the Relationship Between Transformer Architecture and GPT
GPT stands for Generative Pre-trained Transformer, meaning GPT is a large language model developed based on the Transformer architecture by OpenAI. The core idea of GPT is to enhance the ability to generate and understand natural language through large-scale pre-training and fine-tuning. The introduction of the Transformer architecture has significantly improved the model’s ability to understand context, process large datasets, and predict text.
Key Differences:
- Capability Differences: The Transformer architecture enables models to understand context and process large data but does not inherently possess the ability to understand or generate natural language. In contrast, GPT enhances this capability through pre-training on natural language data.
- Architectural Basis:
- Transformer: The original Transformer model consists of an encoder and a decoder, where the encoder processes the input sequence and generates intermediate representations, while the decoder generates output sequences based on these representations. This architecture is particularly suited for sequence-to-sequence tasks like machine translation.
- GPT: GPT primarily uses the decoder part of the Transformer, focusing on generation tasks. It employs unidirectional processing, where each word can only see the preceding words, aligning with the natural format of language models.
- Implementation of Specific Problem-Solving:
- The Transformer is trained for specific tasks, optimizing its performance through simultaneous training of the encoder and decoder.
- GPT, on the other hand, achieves task-specific performance through supervised fine-tuning, requiring only task-specific data without extensive training for each task.
- Application Domains:
- The traditional Transformer framework can be applied to various sequence-to-sequence tasks, while GPT is primarily used for generation tasks, excelling in generating coherent and creative text.
5. Understanding the MOE Architecture
In addition to the Transformer architecture, another popular architecture is the MOE (Mixture of Experts) architecture, which dynamically selects and combines multiple sub-models (experts) to complete tasks. The key idea of MOE is to solve a range of complex tasks by combining multiple expert models rather than relying on a single large model.
The main advantage of the MOE architecture is its ability to maintain computational efficiency while handling large-scale data and model parameters, significantly reducing computational costs without sacrificing model capability.
Transformer and MOE can be used together, often referred to as MOE-Transformer or Sparse Mixture of Experts Transformer. In this architecture:
- The Transformer processes input data, leveraging its powerful self-attention mechanism to capture dependencies in sequences.
- MOE dynamically selects and combines different experts to enhance computational efficiency and capability.
Lecture 2: Differences Between Large Models and Traditional Models
When we talk about large models, we usually refer to LLMs (Large Language Models), specifically those based on the generative pre-trained Transformer architecture like GPT. These models primarily address natural language tasks, unlike traditional models that may focus on images, videos, or speech. Moreover, LLMs are generative models, meaning their main capability is generation rather than prediction or decision-making.
In contrast to traditional models, large models exhibit the following characteristics:
- Ability to Understand and Generate Natural Language: Many traditional models may not understand human natural language, let alone generate it.
- Powerful and Versatile: Traditional models often solve one or a few specific problems, while large models can tackle a wide range of issues.
- Contextual Memory: Large models possess memory capabilities, allowing them to relate to previous dialogue, unlike many traditional models.
- Training Method: Large models are pre-trained on vast amounts of unlabeled text, significantly reducing the need for labeled data compared to traditional models.
- Massive Parameter Scale: Most large models have parameter scales in the hundreds of billions, such as GPT-3.5 with 175 billion parameters, while GPT-4.0 is rumored to reach trillions of parameters.
- High Computational Resource Requirements: Due to their scale and complexity, these models require significant computational resources for training and inference.
Lecture 3: Evolution of Large Models
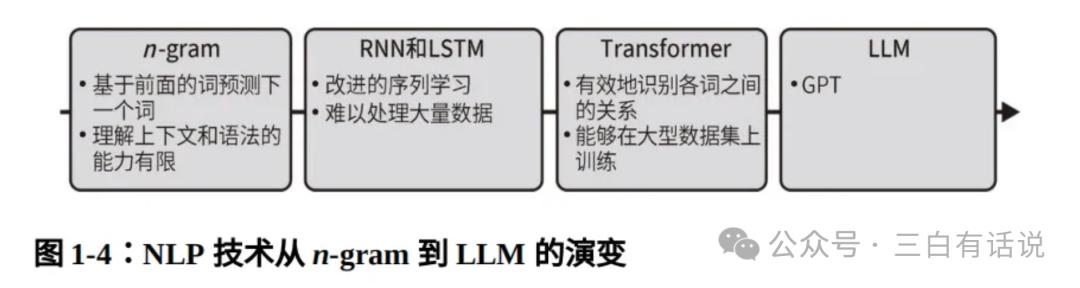
1. Evolution of Generative Capabilities in LLMs
Understanding the evolution of LLMs helps clarify how large models have developed their current capabilities and better understand the relationship between LLMs and Transformers:
- N-gram: The earliest stage of generative capability, primarily solving the prediction of the next word, but limited in understanding context and grammatical structure.
- RNN and LSTM: These models addressed the issue of context length, enabling longer contextual windows but struggled with large data processing.
- Transformer: Combines the predictive capabilities of previous models while supporting training on large datasets but lacks natural language understanding and generation.
- LLM: Adopts the GPT pre-training and supervised fine-tuning approach, enabling the model to understand and generate natural language.
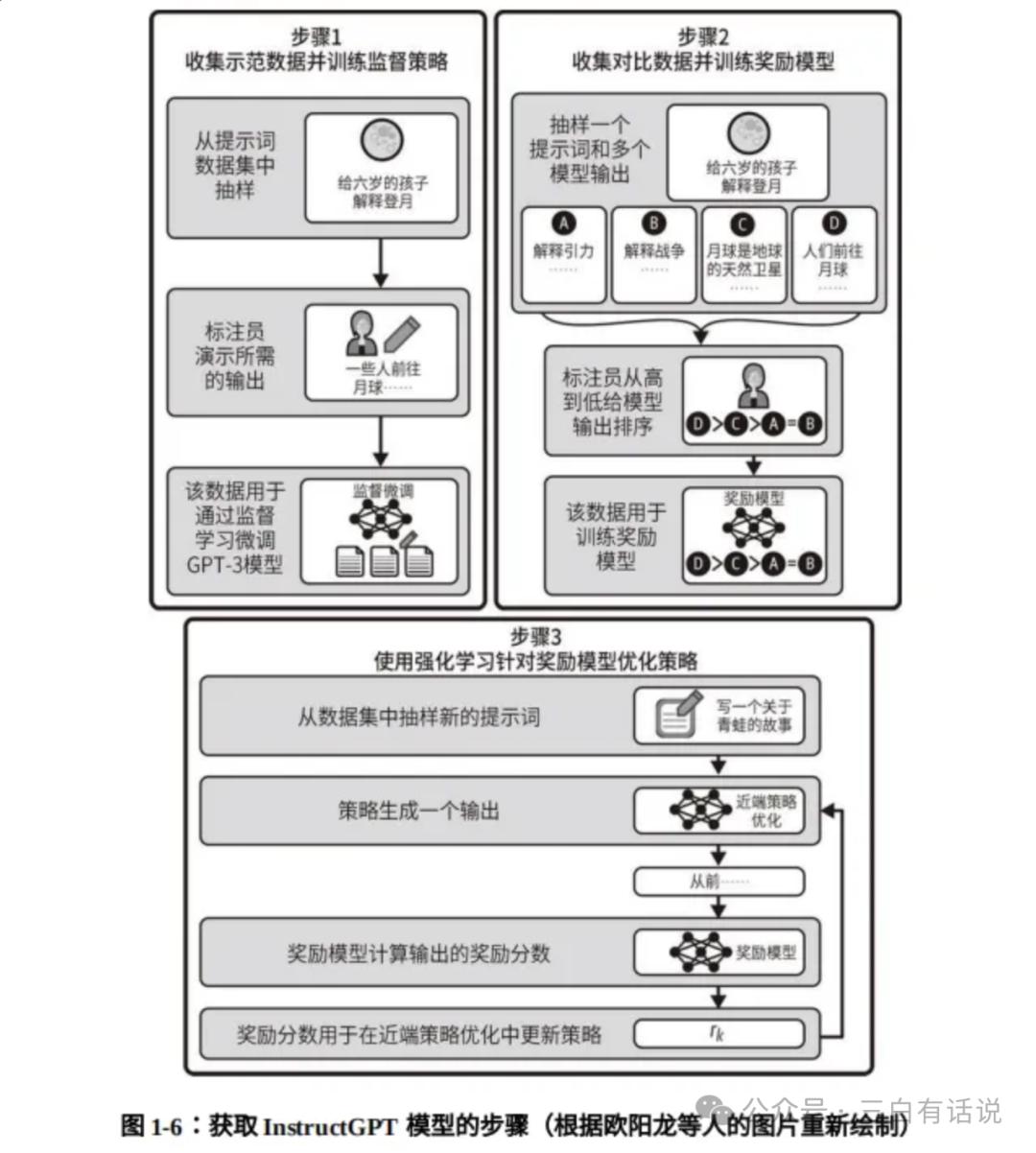
2. Development from GPT-1 to GPT-4
GPT-1: Introduced unsupervised training steps, solving the issue of requiring extensive labeled data. However, its small parameter scale (117 million) limited its ability to handle complex tasks without fine-tuning.
GPT-2: Increased parameter scale to 1.5 billion and expanded training text size to 40GB, enhancing model capabilities but still facing limitations with complex problems.
GPT-3: Expanded parameter scale to 175 billion, achieving strong performance in text generation and language understanding while eliminating the need for fine-tuning.
InstructGPT: To address GPT-3’s limitations, it added supervised fine-tuning and reinforcement learning from human feedback (RLHF) to optimize performance.
GPT-3.5: Released in March 2022, with training data up to June 2021, featuring a larger dataset of 45TB.
GPT-4: Released in April 2023, significantly enhancing reasoning capabilities and supporting multimodal abilities.
GPT-4o: Expected to enhance voice chat capabilities by May 2024.
O1: OpenAI’s O1 model, released in September 2024, focuses on enhancing reasoning capabilities.
Lecture 4: Principles of Text Generation in Large Models
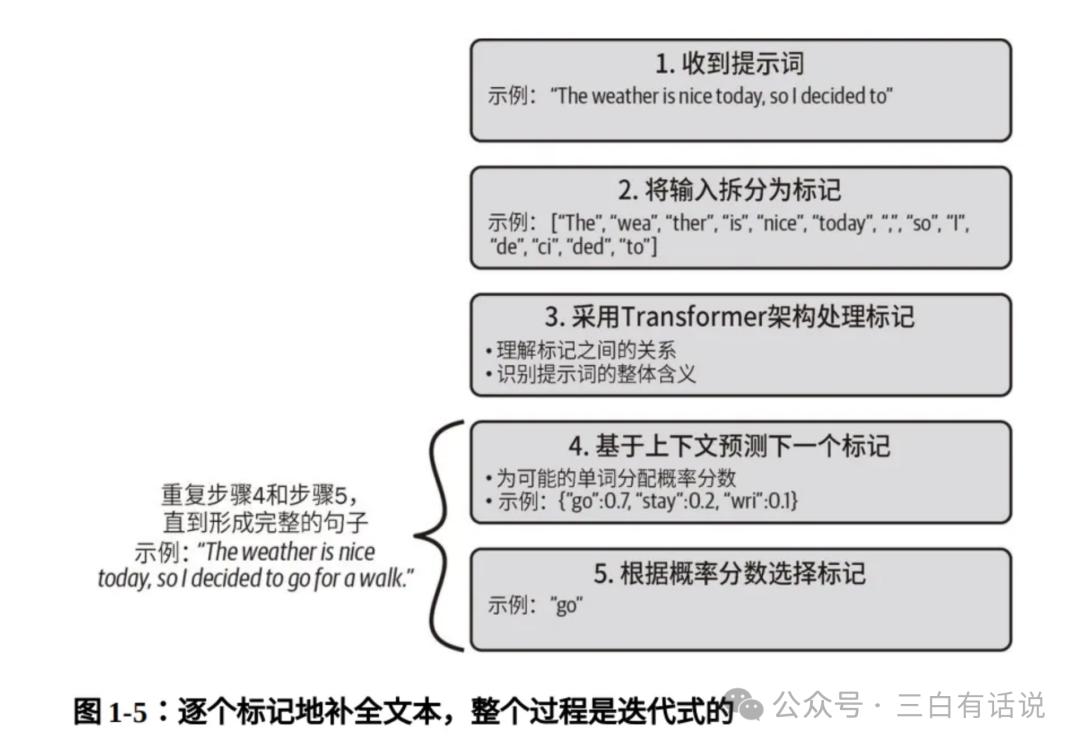
1. How Does GPT Generate Text?
The process of generating text in large models can be summarized in five steps:
- Upon receiving a prompt, the model first tokenizes the input content into multiple tokens.
- It uses the Transformer architecture to understand the relationships between tokens, grasping the overall meaning of the prompt.
- Based on context, it predicts the next token, potentially generating multiple results, each with a corresponding probability.
- The token with the highest probability is selected as the predicted next word.
- This process repeats until the entire content is generated.
Lecture 5: Classification of LLMs
1. Classification by Modality
Currently, large models can be categorized into:
- Text generation models (e.g., GPT-3.5)
- Image generation models (e.g., DALL-E)
- Video generation models (e.g., Sora)
- Speech generation models
- Multimodal models (e.g., GPT-4.0)
2. Classification by Training Stage
- Basic Language Model: A model trained only on large-scale text corpora without instruction or downstream task fine-tuning.
- Instruction-Finetuned Language Model: A model that has undergone instruction fine-tuning and human feedback optimizations.
3. Classification by General and Industry Models
Large models can also be divided into general models and industry-specific models. General models perform well across various tasks but may struggle with specific industry-related data and terminology. Industry models, on the other hand, are fine-tuned for specific domains, achieving higher performance and accuracy.
Lecture 6: Core Technologies of LLMs
While this section may contain many technical terms that are challenging to understand, as a product manager, it is essential to grasp key concepts to facilitate communication with developers and technical teams.
1. Model Architecture: The Transformer architecture is one of the foundational core technologies of large models.
2. Pre-training and Fine-tuning
- Pre-training: A key technology involving training on large-scale unlabeled data, significantly reducing the need for labeled data.
- Fine-tuning: A technique to improve model performance on specific tasks through additional training on targeted datasets.
3. Model Compression and Acceleration
- Model Pruning: Reducing model size and computational complexity by removing unimportant parameters.
- Knowledge Distillation: Training a smaller student model to mimic the behavior of a larger teacher model, retaining performance while reducing computational costs.
Lecture 7: Six Steps in Large Model Development
According to OpenAI’s information, the development of large models typically involves the following six steps:
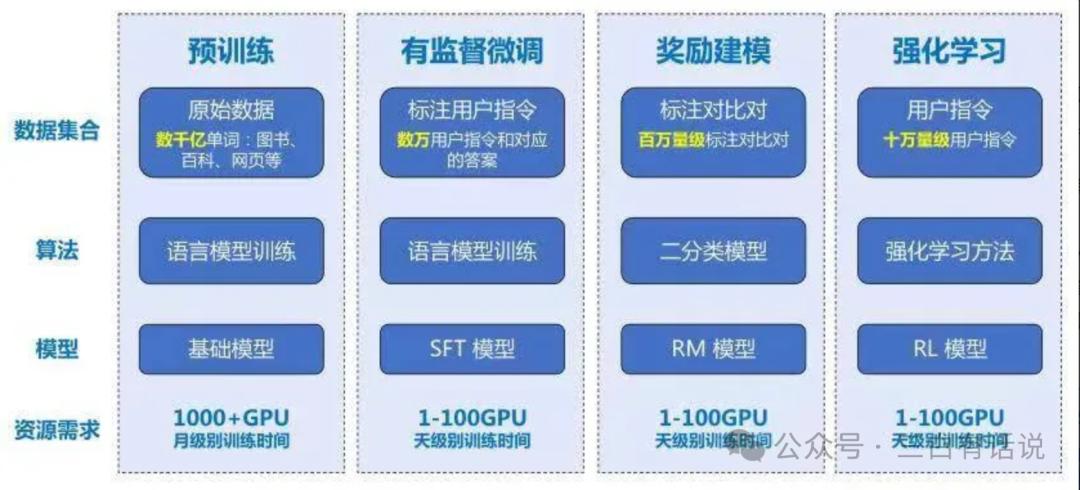
- Data Collection and Processing: Collecting large amounts of text data from various sources and cleaning it to remove irrelevant or low-quality content.
- Model Design: Determining the model architecture, such as the Transformer architecture used by GPT-4, and defining its size, including layers, hidden units, and total parameters.
- Pre-training: The model learns language and knowledge by reading extensive text data, akin to a student absorbing information.
- Instruction Fine-tuning: The process of retraining the model with question-answer pairs to improve its responses.
- Reward Mechanism: Setting up an incentive system to guide the model towards providing valuable and accurate responses.
- Reinforcement Learning: The model learns through trial and error in real-world scenarios to improve its performance.
Lecture 8: Understanding Large Model Training and Fine-tuning
1. Understanding Large Model Training
1) What Data Is Needed for Training Large Models?
- Text data: Used for training language models, such as news articles, books, social media posts, and Wikipedia.
- Structured data: Such as knowledge graphs, to enhance the model’s knowledge.
- Semi-structured data: Such as XML and JSON formats for information extraction.
2) Sources of Training Data
- Public datasets: Such as Common Crawl, Wikipedia, and OpenWebText.
- Proprietary data: Internal company data or paid proprietary data.
- User-generated content: Content from social media, forums, and comments.
- Synthetic data: Data generated through GANs or other generative models.
3) Costs Associated with Training Large Models
- Computational resources: GPU/TPU usage costs, depending on model size and training duration.
- Storage costs: For large datasets and model weights, which can reach TB levels.
- Data acquisition costs: Costs for purchasing proprietary data or cleaning and labeling data.
- Energy costs: Training large models consumes significant electricity, increasing operational costs.
- R&D costs: Salaries for researchers and engineers, as well as development and maintenance expenses.
2. Understanding Large Model Fine-tuning
- Two stages of fine-tuning: Supervised Fine-tuning (SFT) and Reinforcement Learning (RLHF), with differences as follows:

2) Two Methods of Fine-tuning: Lora fine-tuning and SFT fine-tuning.
- Lora fine-tuning adjusts only part of the model’s parameters, suitable for resource-limited scenarios.
- SFT fine-tuning adjusts all parameters, enabling the model to address a wider range of specific tasks.
Lecture 9: Key Factors Affecting Large Model Performance
While there are many large models on the market, differences in their capabilities exist. The five most important factors affecting the performance of large models are:
- Model Architecture: The design, including layers, hidden units, and total parameters, significantly impacts the model’s ability to handle complex tasks.
- Quality and Quantity of Training Data: Model performance heavily relies on the coverage and diversity of its training data.
- Parameter Scale: More parameters typically allow better learning and capturing of complex data patterns but increase computational costs.
- Algorithm Efficiency: The choice of algorithms used for training and optimizing the model affects learning efficiency and final performance.
- Training Frequency: Ensuring sufficient training iterations to achieve optimal performance while avoiding overfitting.
Lecture 10: How to Measure the Quality of Large Models?
From the application perspective, measuring the quality of a large model involves evaluating its performance across several dimensions:
1. Measuring Product Performance
1) Semantic Understanding Ability: Includes understanding semantics, grammar, and context, which determine the quality of interaction with the model. 2) Logical Reasoning: The model’s reasoning ability, numerical computation skills, and contextual understanding are core capabilities. 3) Accuracy of Generated Content: Includes the rate of hallucinations and ability to identify traps. 4) Hallucination Rate: The accuracy of the model’s responses and results, as models sometimes generate nonsensical content. 5) Trap Information Identification Rate: The model’s ability to recognize and handle misleading information. 6) Quality of Generated Content: Evaluated based on diversity, professionalism, creativity, and timeliness. 7) Contextual Memory Ability: Represents the model’s memory capability and context window length. 8) Model Performance: Includes response speed, resource consumption, robustness, and stability. 9) Human-like Quality: Evaluates how “human-like” the model is, including emotional analysis capabilities. 10) Multimodal Ability: Assesses the model’s capability to process and generate across different modalities, including text, images, video, and speech.
2. Measuring Basic Model Capabilities
The three key elements for measuring basic model capabilities are: algorithms, computational power, and data quality.
3. Assessing Model Safety
In addition to evaluating capabilities, safety considerations are crucial. We assess safety based on:
- Content Safety: Compliance with safety management, social, and legal norms.
- Ethical Standards: Ensuring generated content is free from bias and discrimination.
- Privacy and Copyright Protection: Adhering to privacy and copyright laws.
Lecture 11: Limitations of Large Models
1. The Hallucination Problem
The hallucination problem refers to models generating plausible but incorrect or fabricated information. This issue is a significant concern for users and a primary reason for skepticism about model outputs.
Causes of Hallucinations:
- Overfitting Training Data: The model may overfit noise or errors in the training data, leading to the generation of fictitious content.
- Presence of False Information in Training Data: Insufficient coverage of real scenarios in training data can result in the model generating unverified information.
- Inadequate Consideration of Information Credibility: The model may generate content confidently without effectively assessing its credibility.
Potential Solutions:
- Using Richer Training Data: Incorporating diverse and authentic training data to reduce overfitting risks.
- Credibility Modeling: Introducing components to estimate the credibility of generated information.
- External Verification Mechanisms: Employing external sources to validate generated content against real-world facts.
2. The Amnesia Problem
The amnesia problem occurs when models forget previously mentioned information during long dialogues or complex contexts, leading to inconsistencies. Causes include:
- Limitations of Contextual Memory: The model may struggle to retain and utilize long-term dependencies.
- Lack of Examples in Training Data: Insufficient examples of long dialogues or complex contexts in training data can hinder effective memory retention.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.